People immediately get why building rockets and terraforming techniques to send people to Mars is cool. However – if you're the type of person that are so used to tweeting random stuff on Twitter or Threads, or enjoy getting paid and paying someone instantly like I do, you should probably be frightened by the fact that our modern Internet is not prepared for handling communication to and from Mars.
What's even the point of living when we can't access your favorite apps on a new planet we have just set foot on? And how will we pay our workers building terraforming domes on Mars from Earth? We can't ship gold bars or piles of cash to Mars on rockets – that's way too expensive on its own!
Today I want to talk about some of the fundamental challenges of:
- building a new, interplanetary form of the Internet,
- how this fits into building an interplanetary payments system,
- and how these problems can be addressed fairly quickly – as long as people are prepared for fundamental changes to how the Internet works.
Why is this even a problem?
First of all, why can't we just ... well, take the existing Internet and port it over to Mars? That seems like a fairly simple thing to do, if we already have rockets to ship people and physical equipment to Mars.
The problem with interplanetary communication stems from the fact that engineers have never considered nontrivial asynchronicity as a critical engineering factor when the Internet and the World Wide Web was built. Let me explain this a bit further.
Back when the Internet was first being built, engineers ran into this problem where there should be a way for the client to know whether the server they are retrieving data from is still online and available to even start fetching data in the first place. So with TCP/IP they have built this concept called handshakes. The idea for this is fairly simple: the client can send a packet to the webserver, and if the server does not respond with another packet within $x$ seconds, the client (or the server) will consider its counterparty not available, or dead. This makes sense: the client or server can't wait for each other forever because they have limited resources, and there is no way to know whether your counterparty is online or not unless you try first.
This extends to a lot of modern concepts long after TCP/IP was built: for one, let's take async - await future blocks on JavaScript or TypeScript. This basically means: "we will perform this operation that no one knows when it will finish, but when it does, we will consider that operation finished and move on to the next operation block". However for this concept to make sense we need a time threshold to determine whether our counterparty is offline, or just taking a bit longer than usual to process what was requested – because, again, we have no way of knowing whether the counterparty is alive unless we actually try (i.e. liveness). On most systems this threshold is an arbitrarily set number (usually a timeout value) decided by engineers decades ago.
So far this didn't really matter because it is trivial there would be some response as long as the counterparty is online and there aren't technical connectivity issues. But there is a caveat: this only makes sense assuming all communicating parties are on the same planet, i.e. Earth.
This problem of having to wait a trivial period of time for a response is the problem of trivial asyncronicity and can usually be addressed by setting a timeout. This is possible because information over the Internet travels at the speed of light between routing points, and therfore a round-trip to and from a server should not take more than a few seconds. But when we start setting up infrastructure between planets, the laws of physics come into play: that time waiting for a response from a remote server becomes so long it becomes nontrivial.
Not again, Einstein!
Information over the Internet travels at the speed of light, whether they be fiber optic cables or over a copper wire (the difference between these mediums is the bandwidth of which thay can handle at once, i.e. how much data can be processed at a time). The only factor for overhead is processing time spent on routing or computation. The speed of light is fast enough for our needs, but only if we are on the same planet: light can travel approximately 7.5 times around Earth under a second, but not if we are trying to communicate between Earth and Mars.
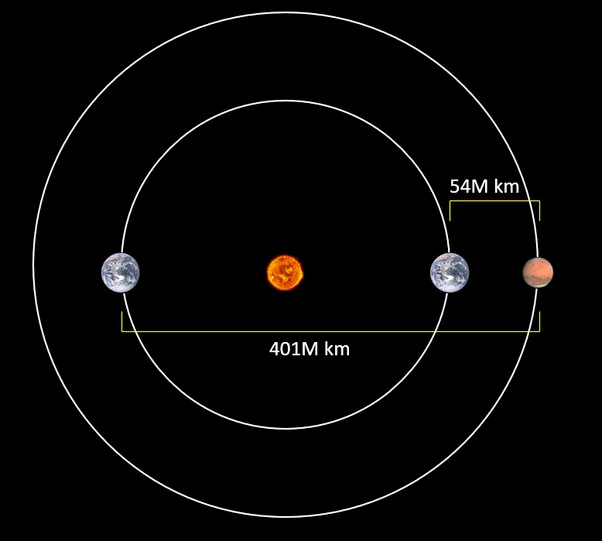
The distance between Earth and Mars may vary greatly because the two planets have different orbiting periods. That distance can be anywhere between 40 million to 400 million kilometers. And for distances this long, even travelling at the speed of light can feel slow. At its shortest distance, it takes approximately 3 minutes for light to travel from Earth to Mars, which sums up to 6 minutes if we want a round trip. At its longest distance, it can take around 24 minutes for light to travel from Earth to Mars, which sums up to an astonishing 48 minutes if we want a round trip. And we didn't put any additional processing or routing times into consideration here, which means we probably need to wait more than 15 minutes when Mars and Earth are at their closest distance, or more than an hour if the two planets are further apart.
Can't we transmit information faster than the speed of light, then? Unfortunately no, unless Albert Einstein is wrong. Einstein's special theory of relativity states no matter or information can travel faster than the speed of light in a vacuum. Some scientists have tried to break this rule through quantum entanglement, but with no luck; while entangled particles do have the same quantum probability state, once the recipient tries to witness what the other entangled particle's state is like, their entanglement breaks, since being of the same state and witnessing that state into classic bits that we can understand are two completely different actions – upholding the 148-year-old rule.
So we clearly need a new way to transmit information without trivial asynchronicity simply to adhere to laws of physics, which breaks a lot of assumptions on how things work on the Internet.
- No liveness assumptions: there is no way to know whether the other party is available or not, unless you wait up to an hour, which is long enough time for the other party to go offline or come back online multiple times.
- No finality assumptions: nothing should ever be considered "final" unless more than enough time has passed for parties on both planets to agree that this piece of information have reached a state where it has been fully synchronized and is difficult to revert. This finality threshold is difficult to determine as the system scales, however, and would be better to simply not have finality at all – participants can have their own finality levels similar to how timeout parameters work on the current Web.
- Routing: specifically fetching information from computer A to B will take a long time, and there should be a way to re-establish connections without relying on liveness factors of machines along the way. Texting from machine A to B will feel more like email than instant messaging, for example.
- Caching: publicly available information should be cached in a way such that nontrivial asynchronicity shouldn't affect data being queried.
Step 1: the ... Inter-Inter-net?
So where do we even begin? Recall that the Internet is inherently a tiered architecture, with ISPs being connected with other ISPs over fiber optic cables and these tier-1 ISPs serving traffic being sent from lower tier networks (hence why it is called the Inter-net: a network of networks). But even these ISPs and IX'es (Internet Exchange Points) are built on the same assumptions as everyone else: trivial asynchronicity. When an IX does not respond within a given timeout, the sending IX will probably try other routing paths as defined with propagated BGP routing paths, which is ... also propagated the same way. TL;DR, nothing will work under the current Internet architecture when the speed of light starts becoming an actual bottleneck.
A simple solution we can think of is to build another network that sits on top of this existing stack to connect with another Internet architecture that exists on another planet (of which only has trivial asynchronicity within its own planet), and then make that common network enforce some rule such that liveness won't be a problem in a nontrivially asynchronous setting.
But how would such a network look like? We first need some agreement on how traffic would route between the two planets' networks in order for any network routing to make sense, and that network should work under a $2 \cdot \Delta t$ asynchronous condition where $2 \le \Delta t \le 30$ is roughly true. We also can't ask any particular party about this because we can't guarantee any liveness for anyone we are querying data from.
Hmm, this sounds a lot like data availability ... because it is essentially the same problem!
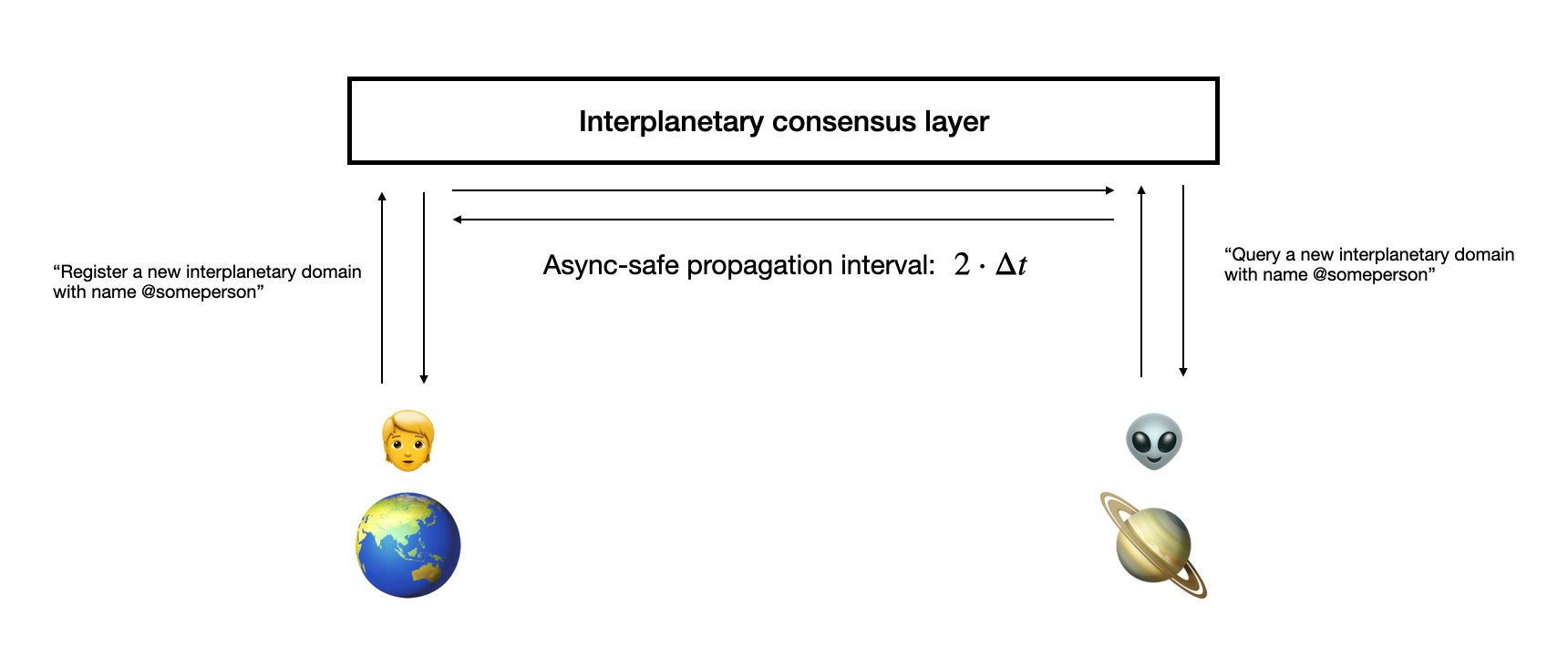
Let's say someone have registered a new interplanetary domain from Earth called @someperson. Because we can't reliably query from a centralized database, all we can do is to propagate this message to some interplanetary consensus layer and wait a minimum of $2 \cdot \Delta t$ for the registration to be safe; this is because any message included after this message, potentially from another planet, must be reverted, and that takes another $\Delta t$ propagation time at minimum to make sure there isn't anyone else trying to do the same thing first before this event happened on one planet. Any updates must also be treated the same way; no event that did not pass the async-safe interval should be considered finalized.
How do we route information between planets? While we can simply pass routing parameters of the other planet and attach it to the interplanetary domain system, we now have the problem of not being able to verify DNS and BGP routing paths reliably from the other planet because of that massive propagation delay. Our best bet would be a solution based on DHT or anything similar, but since this doesn't completely prevent hashed keys from being overwritten before an update is fully propagated, we could:
- hash the entire local subset of all DHT key - value routing pairs within a given local zone, or planet
- periodically publish updates of this local subset hash with a timestamp attached, so the hashed state won't be overwritten
- only provide the local DHT identifier and local network identifier to the sender
We could also have regional CDNs also with a hashed content identifier being puiblished to an interplanetary consensus layer to periodically cache content from other planets, and serve then through a local DHT-like system.
Step 2: Bitcoin, but larger
Okay, but how does this connect with interplanetary payments?
Assuming we have this $2 \cdot \Delta t$ - safe interplanetary consensus layer, now we can start building regional payment networks that are not $2 \cdot \Delta t$ - safe, but significantly faster. Proofs from this regional network can then be propagated to the global consensus network.
But “regional” means something very different once we leave Earth. A more complete stack looks like this:
| Layer | Geographic scope | Typical latency budget | Main job |
|---|---|---|---|
| Global settlement network | Entire Solar System | 30 – 90 min round-trip | Irreversible transfers between planets and moons |
| Planetary or regional chain | Single planet, moon, or Lagrange cluster | 1 – 10 s | Payroll, wholesale trade, large consumer payments |
| Local channels / subnets | City, base, or station | < 500 ms | Retail point-of-sale, machine-to-machine micropayments |
Ultimately, regional settlements would look similar with what we have with blockchain-based settlements today. Interplanetary settlements – transactions happening on the global settlement network – would involve:
- withdrawing from the regional settlement network to the parent interplanetary network;
- making a transfer on the interplanetary network;
- depositing from the parent interplanetary network to another regional settlement network;
- and making a transfer on the counterparty settlement network to the final destination.
Only the global layer must tolerate the worst-case distance (for Mars: roughly 48 min round-trip during conjunction). Layers below it can target human-friendly speeds because they run entirely on local infrastructure.
User experience
There are a few UX tricks we can borrow from good old meat-space finance:
| Trick | Terrestrial analogue | How it works on Mars |
|---|---|---|
| Local liquidity providers | Card-present “authorized but not yet settled” transactions | A liquidity desk front-loads stablecoins locally, credits the end user instantly, and later settles cross-planet once the proof clears. |
| Forward-dated invoices | Wire transfers with value date T + 2 | Wallets encode “effective at block X” so recipients can treat funds as spendable before they’re technically final. |
| Payment channels | Lightning / state channels | Two parties lock collateral on the interplanetary chain once, then exchange signed updates back and forth at LAN speed inside the Mars dome. |
Settlement proofs that can survive the $\Delta t$ abyss
If regional networks are zooming along with their five-second block times (or whatever the hip new zero-knowledge rollup uses by 2040), how do we prove to another planet that a payment really happened without making them download the entire regional ledger?
Enter succinct portable proofs—think of them as cryptographic postcards you can shove into a 128-byte laser burst:
- Commit once, recurse forever.
Every regional chain periodically produces a SNARK/STARK that proves “everything up to block N is valid.” That proof is recursive—meaning each new proof also attests to all the ones before it. The result: a single constant-size blob that represents the entire chain’s history up to the most recent checkpoint. - Checkpoint cadence ≈ local UX, not physics.
A region might emit a new proof every hour. That’s short enough that merchants don’t have to sweat double-spends but long enough that a validator on Phobos can actually finish generating the thing on her laptop. - Bundle, sign, broadcast.
The checkpoint proof plus a Merkle inclusion proof of your payment gets wrapped together, signed by a local light-client committee, and fired at the interplanetary layer. No node on the global network needs to know whether the underlying chain is EVM-compatible, DAG-tastic, or written in COBOL—it just needs to verify the succinct proof.
Result: Earth can accept that a coffee purchase on Mars is final after one global confirmation (≈ at most 30 – 60 minutes) without ever parsing multiple terabytes of history.
Jupiter is $5.2 \text{AU}$ away on average—call it 43 light-minutes one-way. That balloons our $2 \cdot \Delta t$ to ~1.5 hours. But the same principles apply: slap a bigger timeout, raise local collateral requirements, maybe fork in a “Galilean settlement layer.”
Congratulations, you just invented Layer 3!
Bridging value between layers
Transfers may follow a predictable path:
- Lock-and-prove
A company on Mars locks 1,000,000 M-credits in a smart contract vault on the Martian chain. - Generate a succinct proof
Every few minutes the Martian chain exports a zk-SNARK that attests to its state, including the lock event. The proof is a few kilobytes—small enough to embed in a laser or Ka-band burst. - Transmit to the global network
Ground stations hand the proof to the Solar-system chain. Validators there verify it and mint an exactly matching asset (e.g. sM-credit). - Redeem on Earth
When the proof arrives on Earth, an Earth-based exchange can burn the sM-credit and credit the recipient with E-credits on the local chain.
No participant needs the full Martian ledger—only the latest proof. This keeps bandwidth manageable and lets even small colonies participate.
Liquidity and short-term credit
While the proof is in flight, recipients often want to use the money immediately. Two mechanisms cover the gap:
- Liquidity providers post bond on both sides and advance funds to the receiver, collecting a small fee once the proof settles.
- Payment-channel networks allow two parties that frequently transact (for example, a habitat store and its customers) to sign incremental updates off-chain, sweeping the net result to the regional chain once or twice a day.
Both techniques are already used today (foreign-exchange prime brokerage and Lightning-like channels), so the legal and accounting playbooks are familiar.
Managing exchange-rate and counter-party risk
Latency turns price risk into a first-order design parameter. Practical mitigations include:
- Time-windowed FX oracles. A transfer may specify an acceptable exchange-rate band. If the price moves outside the band before the proof lands, the transaction automatically rolls back.
- Collateralized market makers. Liquidity desks must keep margin on the global network that can be slashed if they default while fronting funds.
- On-chain hedging markets. Option and futures contracts let operators lock in rates for the expected propagation interval.
Because latency is weaponized by fraudsters (“Catch me if you can—my chargeback is already halfway to Deimos!”), local providers must post bond on the interplanetary chain. If they mis-credit, their stake can be slashed once truth finally arrives. Think of it as universal KYC: Know Your Crater.
Step 3: Delay-Tolerant Networking (DTN) as the transport backbone
The Internet Engineering Task Force has worked on DTN for decades; the Bundle Protocol (BPv7) already runs on several deep-space missions. For an interplanetary Web and payments stack, BPv7 provides:
- Store-and-forward relays. Ground stations buffer data until the next visibility window, guaranteeing eventual delivery even through solar conjunction.
- Custody transfer receipts. Each relay signs that it has accepted responsibility for a packet, giving higher layers—like the blockchain bridge—the cryptographic evidence they need to decide when to unlock funds or re-route.
- Fragmentation and reassembly. Large proofs or content blobs can be split across many passes without manual intervention.
Deploying DTN nodes at equatorial Mars orbit, Earth–Sun L1, and the Moon’s farside gives every major route at least two independent paths, improving uptime and reducing political single-points-of-failure.
3-A. Why the Bundle Protocol (BPv7) was chosen
BPv7—the version standardized in RFC 9171—sits above any physical or data-link technology and presents a consistent “bundle” abstraction to applications. Each bundle carries:
- a creation timestamp and lifetime (seconds-to-live) so nodes can discard stale traffic without end-to-end clocks;
- a primary block that names the source, destination, and—crucially for payments—a unique, deterministic ID that higher layers can embed in ZK-proofs;
- optional security blocks (BPSec) that provide hop-by-hop or end-to-end authentication and encryption.
Compared to earlier BPv6 deployments, v7 removes several ambiguous header fields and aligns security processing with modern cryptographic suites, raising its technology-readiness level for operational missions.
3-B. Convergence layers and transport mapping
BPv7 rides over “convergence layers” rather than a single transport like TCP. Current space systems use:
| Convergence layer | Typical hop distance | Notes |
|---|---|---|
| Licklider Transmission Protocol (LTP) | Deep-space probe ↔ relay | Designed for long light-time and asymmetric links |
| CCSDS Proximity-1 | Rover ↔ orbiter | Short bursts during over-flight windows |
| UDP / IP | Earth surface network | Fast, inexpensive links between ground stations |
Because the bundle format is identical on every hop, a payment-proof packet generated in a Martian habitat can traverse Proximity-1, LTP, and terrestrial IP without translation or loss of metadata.
3-C. Custody transfer in practice
Large light-time makes end-to-end retransmission impractical. Instead, BPv7 supports custody transfer:
- Node A sends a bundle and requests custody.
- Node B validates and persistently stores the bundle, then returns a signed custody-acceptance signal.
- Once A receives that signal it may delete its local copy; responsibility—and liability—has moved downstream.
A chain of these receipts gives a blockchain bridge cryptographic evidence that the payment proof is physically moving toward the destination, allowing the bridge to release funds incrementally or re-route if a relay fails to accept custody within the bundle’s lifetime. Aggregate custody signaling (ACS) compresses many receipts into one acknowledgment, reducing channel load.
3-D. Routing with Contact Graph Routing (CGR)
Space links are predictable but intermittent. CGR models the network as a time-ordered contact schedule—“link X is up from 13:02 UTC to 13:14 UTC at 256 kbps”—and runs a Dijkstra-like search to find the earliest-delivery path. Because every DTN node already needs the same schedule for antenna pointing, CGR can compute routes autonomously and update them when launches, failures, or political constraints change the contact plan.
Experiments show that for Mars–Earth traffic CGR achieves > 98 % delivery success with queue backlogs under 5 % of link capacity even through a 20-day solar-conjunction outage.
3-E. Topology and redundancy
A minimal interplanetary payments corridor deploys DTN routers at:
- Equatorial Mars orbit – three low-Mars-orbit satellites ensure each surface site sees at least one relay on every pass.
- Earth–Sun L1 – a halo-orbit gateway with uninterrupted line-of-sight to both planets outside solar conjunction.
- Moon farside – an autonomous relay providing an alternate Earth routing path and valuable surface-to-surface testbed.
Each route therefore has two node-disjoint paths; political or technical failure on one branch does not halt settlement.
3-F. Congestion control and quality-of-service
Bundles include a priority flag (bulk, normal, expedited). Relays implement a simple deficit round-robin scheduler so expedited payment proofs pre-empt large science data dumps when contact windows are short. Lifetime expiry acts as a natural back-pressure mechanism: if a bundle waits longer than its TTL, it is discarded—preventing indefinite queue growth during outages.
3-G. Security and operations
- BPSec adds AES-GCM encryption and ED25519 signatures at the bundle layer; keys rotate via a lightweight public-key infrastructure anchored on the solar-settlement chain.
- Telemetry—queue depth, link utilization, custody-timeout counters—flows back to network-operations centers as JSON bundles, enabling predictive rerouting before congestion impacts settlement guarantees.
- Software – NASA’s open-source ION stack already supports all features described here and has flown on Lunar IceCube and PACE pathfinders, reducing integration cost for commercial operators.
With these mechanisms in place, a payment-proof bundle generated in a Martian dome can move hop-by-hop toward Earth, collecting custody receipts at each DTN router, while CGR continuously adapts to changing link schedules. Higher-level payment bridges can track those receipts in near-real-time and provide assurances or partial liquidity long before the bundle itself reaches its final verifier, delivering a user experience that feels immediate even when physics dictates otherwise.
Step 4: Security on a multi-planet scale
- Key custody
Hardware security modules rated for radiation and extreme temperature swings are required at every Tier-0 relay. The same cryptographic curves (e.g., BLS12-381) are used across layers to simplify verification software. - Consensus diversity
To avoid correlated failure, the global network should employ a different consensus algorithm (for example, a proof-of-stake BFT variant) than any subordinate planetary chain. - Incident response
Because patch deployment cannot be instantaneous, critical-path software is shipped with time-locked kill switches—pre-audited code that activates only after a two-week waiting period announced on the global chain. This provides a predictable window for validation and rollback.
4-A. Key custody beyond Earth-orbit
Hardened hardware. Tier-0 relays—Earth–Sun L1, Mars orbit, Moon farside—house FIPS 140-3 Level 4 HSMs built on silicon qualified for ≥ 200 krad total-ionising-dose and –150 °C ↔ +120 °C operation. Each relay runs a 3-of-5 threshold cluster: three HSMs must agree before a private key can sign custody receipts or validator messages, so a single radiation upset cannot unilaterally authorise transfers.
Unified curves. All layers use the same pairing-friendly curve family (BLS12-381 for signatures, BN254 for SNARK proving) to let low-power nodes carry one verification library rather than several, simplifying audits and lowering supply-chain risk.
Secure provisioning. Keys are generated on-device, never exported, and their public components are published on the global settlement chain together with an attestation bundle (serial + firmware hash). Any field replacement must present a new on-chain attestation before the network will accept its signatures.
Lifecycle rotation. Key epochs last six months; rotation transactions must be scheduled at least one epoch in advance. This aligns with typical Mars–Earth logistics cycles and prevents “emergency” key swaps that could mask coercion.
4-B. Consensus diversity to contain correlated faults
The architecture intentionally avoids “one-size-fits-all” consensus:
| Layer | Consensus example | Fault model mitigated |
|---|---|---|
| Global solar-settlement | Proof-of-stake BFT with ⅔ super-majority | Sybil resistance without wasteful energy; validator distribution across planets limits jurisdictional capture |
| Planetary chains | Lightweight PoS or low-difficulty PoW | Handles local outages; simpler validator incentives; faster block times |
| Habitat or dome subnets | Federated Raft / permissioned BFT | Runs on LAN; recovers quickly after dust-storm blackouts |
A bridge smart-contract refuses to import a proof that originates from a chain running the same client code and consensus as itself. This “interlayer firewall” constrains the blast radius of a shared-code vulnerability.
4-C. Incident-response strategy when latency is hours
- Time-locked kill switch. Critical modules ship with a dormant branch—formally verified and hashed into the genesis state—that can force the chain into safe-mode (no new asset mints, only transfers of existing balances). Activation is a two-step transaction announced on the global chain; it arms after a 14-day delay, giving every colony time to audit and, if necessary, veto.
- Deterministic hot-patches. If a non-critical bug appears, maintainers publish a signed patch plus its reproducible-build hash on the global chain. Nodes compile and stage the binary but only switch over once ≥ 75 % of stake weight has flagged readiness.
- Out-of-band revocation. Should a relay be compromised physically, its public key can be revoked by a ⅔ stake vote. Planetary-scale latency means the rogue relay may remain live for hours, so bridges impose risk-weighted limits—small transactions may still pass; large ones queue until revocation propagates.
4-D. Supply-chain integrity and reproducible builds
- Singular toolchains. Each reference client releases a Dockerfile pinned to specific compiler, linker and library versions; binaries must hash to the value asserted on-chain before a node will load them.
- Hardware provenance. FPGA bitstreams and firmware blobs are signed by two independent labs; receiving stations compare signatures before flashing.
- Continuous audit. Static-analysis and fuzzing artefacts are themselves archived as Merkle-rooted artefacts that anyone can challenge on the settlement chain.
4-E. Monitoring and anomaly detection
- Telemetry commitments. Every relay emits a 10-minute summary bundle (queue depth, CPU temp, radiation dose). The SHA-256 of that bundle is anchored on its planetary chain; if the node later serves data that does not match, the discrepancy is provable.
- Cross-layer alarms. If global validators observe a custody-receipt gap longer than 2x the advertised contact window, they throttle that route and shift traffic, preventing back-pressure from cascading through the payment system.
By hardening keys against space conditions, diversifying consensus, and designing an incident-response workflow that respects the unavoidable light-time delay, the interplanetary payments network stays resilient even when individual links—or entire planetary segments—experience faults, coercion, or physical compromise.
Wrapping up: boring plumbing, shiny future
An interplanetary Internet and payments stack sounds exotic, but the core recipe is straightforward:
- Accept that latency is immutable physics, not an engineering bug.
- Separate local fast systems from slow global consensus, glue them with succinct proofs.
- Incentivize honest bridging via collateral and slashing.
- Cache-all-the-things so humans never stare at loading spinners for longer than they shower.
Do that, and when the first bartender opens shop under Olympus Mons, you’ll order a “dust-storm martini,” pay with a blink of your retina implant, and the bar’s liquidity provider will settle the tab back to Earth long after you’ve stumbled home in your pressure suit.
The universe is big; our protocols just have to grow up to match it. ■
